Настало время наконец приступить к понимаю основ и принципов работы виртуальных сетей в NSX-T. В предыдущих частях мы описывали что такое NSX, для чего он нужен и подготовили инфраструктуру к установке этого продукта. В этой статье мы познакомимся с архитектурой его работы на уровне L2 сетевой модели. Разберемся наконец некоторые из ранее упоминавшийся терминов и проследим за пакетами VM, как они путешествуют в пределах одного L2 домена. В этом выпуске:
- Архитектура L2 NSX-T
- Сегменты
- Тунелирование
- Протокол Geneve
- TEP интерфейсы
- Segment Profiles
- SpoofGuard
- IP Discovery
- MAC Discovery
- Segment Security
- QoS
- Путь пакетов NSX-T L2
- TEP/MAC/ARP таблицы
- Путь пакета Unicast
- Путь пакета BUM
Архитектура L2 NSX-T
В этом разделе опишем из чего состоит L2 в NSX-T технически. Как мы знаем из предыдущей статьи у нас есть Транспортные Зоны, которые деляться на Overlay и VLAN по типу. Тип Зон определяет на основе какой технологии (VLAN или Overlay) будет происходить разделение широковещательных L2 доменов внутри них. Если с VLAN все понятно — мы используем такие сегменты в качестве линков в физический мир (а как — это тема для следующих частей), для управления хостов, сеть которых переехала на N-VDS и просто для VM, которые должны находиться в каком-либо VLAN по тем или иным причинам. То с Overlay нам предстоит разобраться. Но давайте по порядку. Снизу изображена концептуальная архитектура L2 на NSX-T.
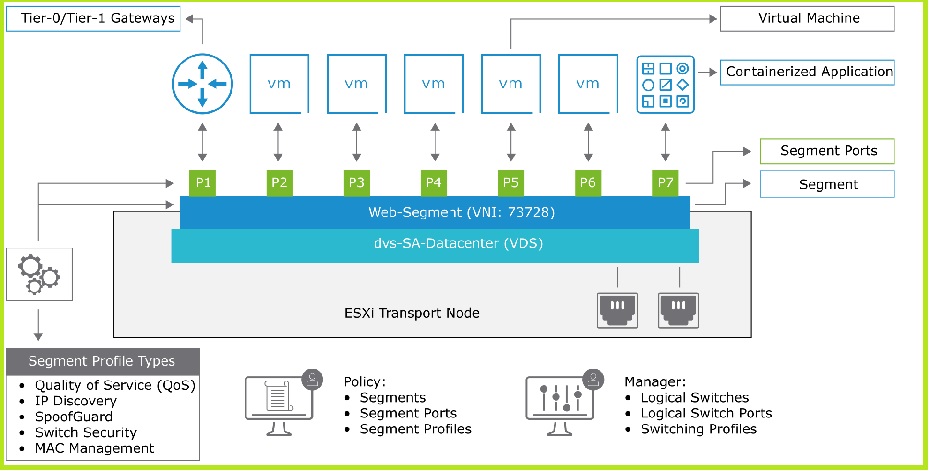
Мы видим виртуальный свитч, который добавляется на транспортную ноду, об этом написано в прошлой статье. Физические аплинки сервера, назначенные свитчу, через которые ходят пакеты в физическую сеть. Видим Сегмент, который является по сути порт-группой на виртуальном свитче. А также порты на этом сегменте, к которым подключены виртуальные машины, контейнера и шлюз. Segment profiles, определяющие политики и некоторый функционал NSX-T на L2 уровне. Единственно тут не хватает TEP интерфейсов для полноты картины, но мы не обделим их вниманием в этой статье. Давайте приступим к погружение во все это.
Segments
Сегменты NSX-T. Так же называются Logical Switches. Эти два термина обозначают одно и то же, но в разных контекстах (Segment – Policy Plane/Logical Switch – Management Plane). Сегменты создаются внутри транспортной зоны и как мы помним из предыдущих статей, не могут выйти за ее пределы. Транспортная Зона диктует на каких хостах будет доступен определенный L2 сегмент.
Сегмент это один виртуальный широковещательный домен L2 в NSX-T. По сути это одна порт-группа на виртуальном коммутаторе, обеспечивающая соединение между портами VM по L2 внутри и между Транспортных Нод (ESXi хостов). Если мы зайдем в vCenter, то сегменты NSX-T будут видны нам как порт-группы с немного измененными иконками в зависимости от того какой виртуальный свитч мы выбрали в Профиле Транспортной Ноды (подробно описано в прошлой статье).
Сегменты бывают двух типов – VLAN и overlay.
VLAN сегменты ничем почти не отличаются от обычных порт-групп на виртуальном коммутаторе и используют 802.1Q заголовок для разделения L2 доменов. VLAN сегменты просты и не имеют возможности пользоваться распределенной маршрутизацией NSX, но в остальном имеют похожие свойства и настройки, что и overlay сегменты. Могут быть созданы только в Транспортной Зоне VLAN типа.
Overlay сегменты более сложны. Они являются более «виртуальными» чем VLAN-ы и могут пользоваться всеми функциями NSX, предоставляя больше гибкости и масштабируемости. Overlay сегменты работают поверх VLAN-ов, а точнее поверх одного транспортного VLAN-а, который нужен только для транспортировки пакетов в пределах overlay сегмента по физической сети. Каждому overlay сегменту присваивается идентификатор (VNI), Похожий на VLAN ID. VNI может принимать значения от 5000 до 16777216. То есть мы можем напилить в среднем около 16 миллионов Overlay сегментов, в отличие от максимума 4095 возможного с технологией VLAN. В данной статье речь пойдет преимущественно о overlay сегментах. Ну и стоит упомянуть что overlay сегменты создаются только внутри Overlay Транспортной Зоны.
Теперь о том, как происходит обмен пакетами между членами одного overlay сегмента. Мы знаем, как это работает в обычных порт-группах с настроенным VLAN, к примеру, на VDS. Машина VM-1, расположенная на гипервизоре A отправляет пакет на машину VM-2, расположенную на гипервизоре B. Итак, гипервизор A обрабатывает пакет, вешает на него тег с VLAN ID и пускает с аплинка в физическую сеть. Коммутатор на основе VLAN ID и MAC таблицы пропихивает пакет в нужный порт к аплинку гипервизора B. Гипервизор B принимает пакет, снимает с него тэг и пропихивает в VM-2. Все. Так же это происходит в сегменте, созданном в VLAN TZ на NSX. Но как это происходит в Overlay сегменте?
Тунелирование
А происходит это с помощью тунелирования. Пакет VM-1 инкапсулируется протоколом Geneve и отправляется по физической сети до гипервизора с VM-2 на борту по туннелю Geneve.
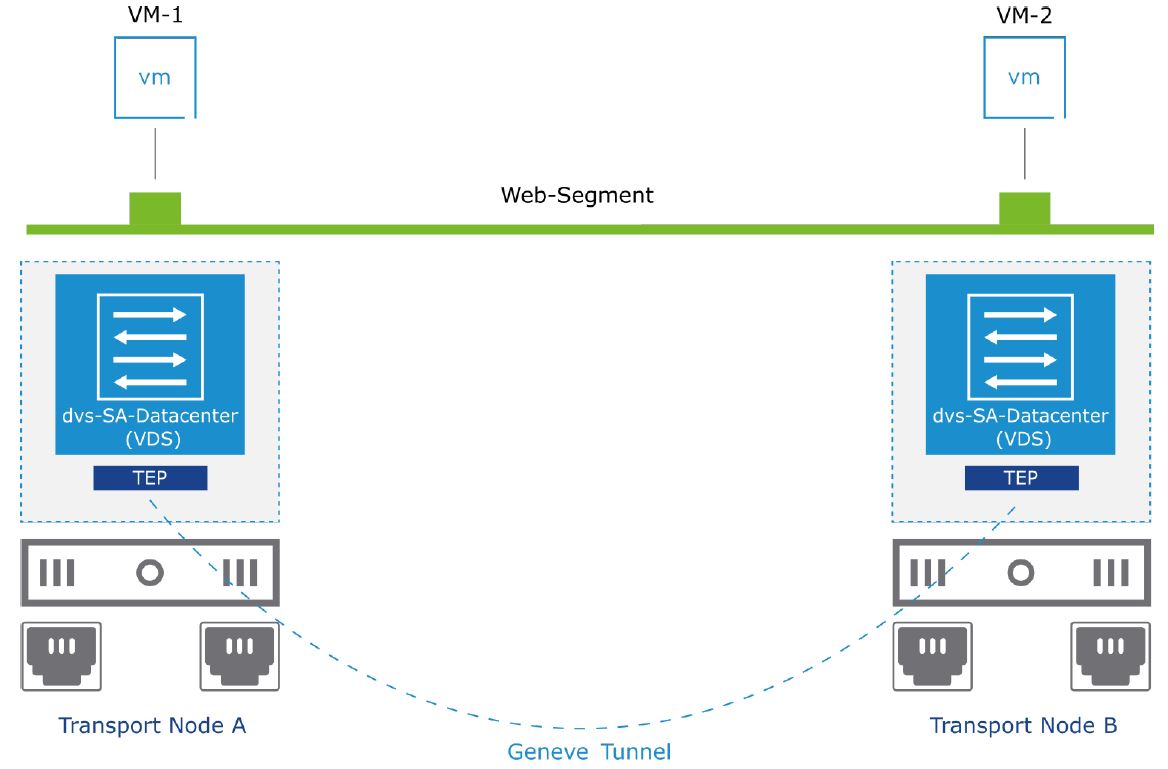
Туннели подымаются между TEP интерфейсами Транспортных Нод, изолируя Overlay сегмент от физической сети. В данном случае у нас изображен туннель между TEP интерфейсами гипервизоров A и B. Overlay сегменты основаны на туннелях, которые изолируют виртуальную сеть от физической. Эта изоляция достигается путем инкапсуляции пакетов VM в заголовок протокола Geneve. Инкапсулированные пакеты путешествуют между Транспортными Нодами по физической L2 или L3 сети. IP адресом источника и назначения такого пакета являются адреса TEP интерфейсов. Сам же оригинальный пакет VM скрывается за заголовком Geneve и будет распакован, и передан VM-2 по прибытию на TEP хоста B.
Туннели подымаются между хостами при включении на хостах VM. В списке транспортных нод можно посмотреть на каких хостах туннели есть и до каких хостов они ведут.
Это на самом деле очень важно. Потому что если до каких-то хостов туннели не подымятся, то VM между этой парой хостов не смогут обмениваться траффиком. Такое случается, когда в профилях хостов указан неправильный VLAN для транспортного трафика либо какая-то проблема в маршрутизации туннельного трафика, если TEP интерфейсы у хостов в разных подсетях. Одним словом, если какая-то машина не может достучаться до другой и машины на разных гипервизорах – смотри туннели.
Протокол Geneve
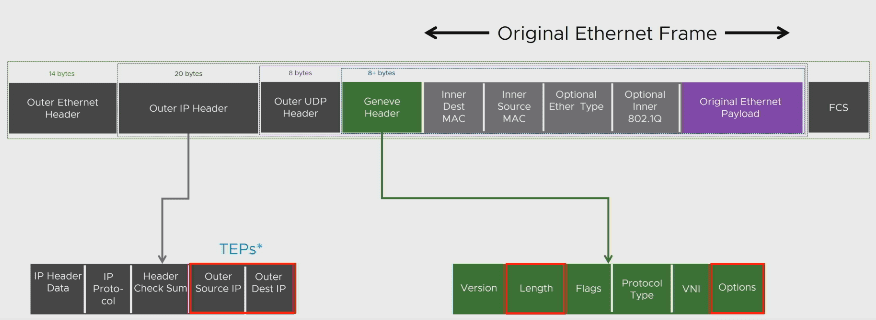
Теперь про то что эти туннели строит – протокол Geneve (Generic Network Virtualization Encapsulation). Это открытый протокол туннелирования, который инкапсулирует L2 фреймы поверх L3. Его можно сравнить с другими аналогами — VXLAN, NVGRE, и STT. Но по сравнению с ними он более гибок и функционален. Его функциональность достигается более многочисленными полями в служебном заголовке, которые могут быть использованы для различных нужд в будущем. Для сведения VMware NSX-V использует протокол VXLAN для тех же целей.
Так как пакет Geneve имеет свой собственный заголовок L3 и L2, туннели между Транспортными Нодами могут простираться не только в пределах одной подсети или VLAN, но и за их пределами. То есть трафик туннелей может маршрутизироваться, а TEP интерфейсы Нод находиться в разных физических L2 доменах.
Виртуальная машина VM-1 на хосте A отправляет пакет, предназначенный VM-2, расположенной на хосте B, машины в одном сегменте. Гипервизор А понимает по служебным таблицам (о них потом), что VM-2 находиться на гипервизоре B (с которым у него установлен туннель) берет пакет и не меняя в нем ничего инкапсулирует его в Geneve заголовок. В заголовке указывается адресом источника – IP своего TEP, а адрес назначения – IP TEP интерфейса хоста B, с которым у него есть туннель. Протокол доставки UDP, а порт назначения 6081. Пакет отправляется в путешествие по VLAN, казанному в Профиле Транспортной Ноды гипервизора A как Транспортный VLAN. Итак, пакет доставляется до хоста B, тот его рассматривает, понимает, что он прилетел к машине, расположенной на нем, декапсулирует пакет, снимая Geneve заголовок и пропихивает оригинальный пакет в порт виртуальной машины VM-2. Вуаля. Если трафик мультикастовый или броадкастовый, то инкапсулированный фрейм летит на несколько гипервизоров что бы быть доставленным всем портам в сегменте.
Особенности Geneve:
- Использует UDP для доставки пакетов.
- Использует порт 6081.
- Использует 24 битный VNI.
- Поддерживает IPv4 и IPv6.
- В заголовке присутствует куча дополнительных полей, зарезервированных на будущие нужды NSX, собственно именно благодаря функциональному заголовку Geneve и «отжал» у VXLAN позиции в NSX-T.
- Позволяет делать такой же offloading на физическом адаптере, как и VXLAN.
- Классное название.
TEP интерфейсы
Про них было уже много рассказано сегодня. Они являются сетевым горлышком для обмена трафиком внутри Транспортной Зоны. Geneve туннели начинаются и заканчиваются этими интерфейсами.
TEP создается на Транспортной Ноде при установки NSX. Он может быть и не один. Количество TEP интерфейсов на хосте или Edge ноде зависит от Uplink Profile, а точнее от количества Active Uplinks. Почему? Потому что если активных аплинка два, а TEP один, то инкапсулированный трафик будет задействовать только один физический аплинк, а второй будет простаивать. Не оптимальненько. Поэтому сколько активных аплинков, столько и TEP интерфейсов. Соответственно и количество подымаемых туннелей увеличится на хосте, если TEP-ов больше.

В интерфейсах хоста в vCenter, TEP-ы так же видны и используют персональный tcp/ip stack – «nsx-overlay», но в консоли ESXi данный стек носит другое название – «vxlan». Имейте это ввиду, когда производите траблшутинг.
Каждый из TEP-ов на хосте будет стремиться поднять туннель с каждым TEP-ом на каждом другом хосте в инфраструктуре NSX-T. Например, у нас три хоста и на каждом по два TEP. На каждом хосте будет 8 туннелей.
Иногда приходиться диагностировать соединения до других TEP-ов. Например, когда не подымается какой ни будь туннель. Причин тому может быть много, и они могут быть скрыты в совершенно разных аспектах настройках как виртуальной сети, так и физической. Первый шаг, который нужно предпринять для диагностики – это проверка сетевой доступности и корректно настроенного MTU. Конечно тема траблшутинга не рассматривается здесь, но проверить правильность конфигурации MTU бывает необходимо на шаге деплоя. Ниже команда, с помощью которой мы можем проверить проходят ли пакеты нужного нам размера до другого конца TEP.
vmkping –I vmk10 –s vxlan - 30.30.30.104 –dЗапускаем подключившись к одному из хостов ESXi, между которыми лежит туннель.
-I vmk10 – определяем исходящий интерфейс.
-S vxlan – определяем tcp/ip stack, который работает на интерфейсе, на TEP может работать только ‘vxlan’ и указать его необходимо иначе команда не заработает. Как говорилось выше, в интерфейсе vCenter, стэк носит имя «nsx-overlay».
30.30.30.104 – ну ты понел.
-s 1472 – задает количество байт ICMP в пакете. Если прибавим 28 байт (заголовок ICMP/заголовок IP/Ethernet), то получим 1600. Наш необходимый MTU.
-d – очень важный флаг, он отменяет фрагментацию кадров. Нужен что бы наши 1472 байт не раскидались по нескольким пакетам.
Создание сегмента
Давайте уже создадим сегмент в NSX-T. Идем в Network> Segments> add segment. Нам откроется форма ниже. Вводим имя и пробежимся по выделенным полям.

- Выбираем к какому логическому маршрутизатору будет подключен данные сегмент. Об этом в следующих статьях.
- Выбираем транспортную Зону в пределах которого будет развернут этот сегмент.
- Задаем адрес шлюза для этого сегмента. Да все верно. Если мы указали IP шлюза и подсоединили сегмент к виртуальному маршрутизатору в пункте 1, то в этом сегменте создается порт для роутера и ему назначается IP. Сегмент становиться маршрутизируемым.
- Тут мы можем увидеть все подключенные порты VM к этому сегменту.
- Тут задается VLAN ID для сегмента в случае если создаем его в VLAN Транспортной Зоне. В случае Overlay оставляем пустым. VNI для сегмента будет назначен автоматически.
Остальные поля нам пока не нужны. Нажимаем SAVE и сегмент готов. Через секунду-две статус сегмента станет зеленым. Это значит, что Policy Plane принял к исполнению наши требования, передал это на Management Plane, а тот на CCP и на Data Plane. А затем обратно пришел рапорт об успешно принятой конфигурации и создании объекта.
К слову о Management Plane. Если мы переключим контекст меню на manage, то сегменты предстанут перед нами как Logical Switches. Интерфейс создания тоже будет немного отличаться, но ключевые параметры останутся.
Segment Profiles
В этом разделе поговорим о профилях сегментов. Что это такое и для чего нужно. В процессе создания сегмента NSX вы наверняка заметили внизу раскрываемый раздел с одноименным названием, который недоступен для редактирования до момента завершения создания сегмента. Профили сегментов определяют, как будет работать тот или иной функционал в сегменте. Профиля бывают:
- SpoofGuard
- IP Discovery
- MAC Discovery
- Segment Security
- QoS
Каждый из них определяет конфигурацию определенного набора служб. Профиля применяются на сегменты и на порты в сегменте. Работает это так. Если назначен профиль на сегмент, а на порт персонально нет, то порт наследует профиль сегмента и если профиль на сегменте поменялся, то и на порту тоже. Но если на порт задан профиль персонально, то он будет преобладать и в случае если на сегменте поменяется профиль, то на порту останется старый.
В NSX присутствуют Default Segment Profiles.

Редактировать их не получиться. Но можно посмотреть их настройки, раскрыв стрелку.
Теперь давайте пройдемся и опишем каждый профиль.
MAC Discovery Profiles
Этот профиль определяет будет ли работать MAC Learning и будет ли возможность поменять MAC адрес на виртуальной машине в сегменте безнаказанно. Давайте детально.

MAC Learning – функция, позволяющая выучить множественные дополнительные MAC адреса, если они вдруг появились за определенным портом в сегменте. К примеру, у нас есть один подключенный к сегменту порт виртуальной машины. У машины есть MAC адрес на виртуальном интерфейсе, NSX его знает, знает на каком он порте, и шлет фреймы, предназначенные ему в этот порт. И тут вдруг с этого самого порта начинают исходить фреймы, MAC адрес источника которых отличается от MAC адреса, который знает NSX. Так вот, если MAC Learning включен в этом профиле, то NSX будет запоминать эти «левые» маки и направлять пакеты, предназначенные им в порт, с которого они «засветились». Это очень подходит если у нас развернуты вложенные ESXi хосты, на которых работают виртуалки, общающиеся по сети.
У MAC Learning есть параметр времени, на протяжении которого NSX будет помнить выученный «левый» MAC если тот перестал использоваться и пакеты с от него не летят. Этот параметр не конфигурируется и составляет 10 минут. Это значит, что спустя десять минут после того как «левый» мак перестал слать пакеты, NSX удалит его из MAC таблицы сегмента.
MAC Limit задает максимальное количество маков, которое NSX может выучить. По умолчанию 4096 и увеличить это значение можно только после включения MAC Learning.
MAC Limit Policy – Определяет что делать с пакетами, MAC адрес источника которых неизвестен NSX-у по причине преодоления лимита, настроенного в MAC Limit. Deny – дропать пакеты исходящие от неизвестных MAC адресов, а пакеты направляемые таким адресам (неизвестным) помечать как unknown unicast. И если включен Unknown Unicast Flooding такие пакеты будут разосланы всем портам в сегменте, а если не включен, то будут дропнуты. Alloy – пропускать пакеты исходящие от неизвестных маков, пакеты предназначенные им (unknown unicast) пропускать в случае если включен Unknown Unicast Flooding.
Unknown Unicast Flooding – про это описано выше. Если включен, то пакеты с неизвестным MAC адресом назначения будут рассылаться во все порты сегмента. Если выключен – дропаться.
MAC Change – определяет как будет реагировать NSX на смену виртуальной машиной своего MAC адреса, прописанного в vmx файле. Данная опция доступна только на ESXi хостах, на KVM работать не будет, что бы мы тут не настроили. По умолчанию эта функция отключена и это значит, что если VM сменила мак, то ее трафик будет дропнут и сеть у нее не будет работать.
IP Discovery Profiles
NSX нужно знать IP адреса виртуальных машин для ряда функций:
- ARP/ND Suppression, которая позволяет минимизировать широковещательный ARP трафик между VM.
- Distributed Firewall – распределенный брандмауэр.
- SpoofGuard – механизм для блокировки дублирующийся IP.
Что бы эти адреса узнать NSX использует несколько технологий, в число которых входит:
- DHCP/DHCPv6 snooping
- ARP/ND snooping
- VMware Tools
DHCP/DHCPv6 Snooping – NSX следит за трафиком DHCP и запоминает какой MAC получил какой IP. Позволяет определять IP порта, если не настроен статический адрес.
ARP Snooping – слушается ARP трафик машин и на основе ответов происходит сопоставление MAC-IP отвечающей машины. Определяет IP порта, когда задан статический IP в виртуальной машине.
ND Snooping – то же самое что и ARP только для IPv6.
VMware Tools – установленные на VM тулзы рапортуют о IPv4 и IPv6 адресах, которые настроены на интерфейсах. Работает только на машинах, расположенных на ESXi естевственно.
Сопоставленные MAC/IP, выученные на каждом порту с помощью вышеописанных служб, записывает в так называемые Address Bindings. У каждого порта в сегменте есть свои Bindings.
Address Binding это сопоставленные IP/MAC/VLAN (если есть, у портов в Overlay TZ всегда равен нулю) и закрепленные за портом в сегменте. Посмотреть эти биндинги можно переключив интерфейс Networking в режим manager. Затем зайти в Logical switches> Ports и выбрав интересующий нас порт. Открываем Address Bindings и видим различные типы биндингов.

Auto Discovered Bindings – содержит полученные IP/MAC на порту в результате работы одного из методов описанных выше.
Manual Bindings содержит то же самое, но заданное вручную администратором.
Ignore Bindings – список IP/MAC, который NSX известен из каких либо источников, но который игнорируется системой. В этот список можно добавить биндинги вручную. Иногда такое требуется если на маке порта засветился адрес, который по каким-либо причинам нежелателен.
Realized Bindings – а это уже биндинги на которые ориентируются службы, перечисленные в начале. Как видим присутствующий биндинг получен с помощью ARP snooping.
Итак, NSX-T c помощью определенных в профиле функций узнает IP/MAC порта, заносит его в Auto Discovered Bindings, затем плюсуется запись из Manual Bindings (если она есть), из этого списка удаляются записи, перечисленные в Ignore Bindings (опять же если они есть) и все что «уцелело» падает в Realized Bindings, на которые и ориентируется NSX.
Вернемся к нашему IP Discovery профилю, который и определяет, как и с помощью каких технологий будут заполняться Auto Discovered Bindings в определенном сегменте или даже на определенном порту (как мы помним, сегмент профиля можно назначать и на порты). В данном профиле мы можем задавать с помощью каких технологий будет определяться IP порта, отключая ненужные. В профиле по умолчанию IPv6 адреса не определяются так как отключены DHCPv6 Snooping, ND Snooping, VMware IPv6 и что бы нам это исправить, нужно создать дополнительные профиля, в которых включить их.

По умолчанию ARP и ND Snooping работают в режиме trust on first use (TOFU). В этом режиме если IP адрес узнан и добавлен в Realized Bindings List, то он остается там навсегда. Можно отключить этот режим соответствующим переключателем в профиле и тогда ARP/ND Snooping будет работать в trust on every use (TOEU). В этом режиме запись MAC/IP будет существовать в Realized Bindings List только определенное время (заданное в ARP ND Binding Limit Timeout в минутах), после которого будет заменяться на ново изученную. TOEU подходит для сегментов, где IP у машин меняются периодически.
DHCP/DHCPv6 snooping и VMware Tools работают всегда в TOEU. Потому как динамические адреса имеют свойства меняться и их «приколачивание» к порту тут неуместно.
Так же у нас есть ARP и ND Snooping Limit настройки. Они определяют лимит IPv4 и IPv6 адресов, закрепленных за портом.
Duplicate IP Detection – эта функция проверяет, присутствует ли выученный IP адрес в Realized Binding List других портов. Другими словами, проверяет есть ли такой же IP в данном сегменте. И если есть, то свежий дублирующийся адрес не добавляется в Realized Binding List своего порта и соответственно не учитывается. Но и не удаляется. Он тусит в Auto Discovered Bindings списке своего порта до тех пор, пока адрес, который он дублирует не исчезнет из сегмента по какой-либо причине. После этого он перемещается в Realized Binding List своего порта и будет учтен.
Но что делать если сразу несколько портов «засветили» одинаковым адресом, да к тому же еще и присутствующем в системе? NSX вызывает копов. Дело в том, что, когда NSX определяет IP в сегменте, он добавляет к его записи в Auto Discovered Bindings листе метку времени, когда этот IP «засветился». И когда адрес, который дублируют другие порты исчезает из сегмента, в Realized Binding List своего порта попадает та запись, метка времени которой старше, а более «младшая» продолжает «чилить» в Auto Discovered Bindings своего порта.
QoS profile
Данный профиль позволяет вешать на трафик Overlay сегмента метки, определяющие приоритетность трафика. Что бы устройства в физической сети – коммутаторы и маршрутизаторы ориентировались на эти метки и гарантированно предоставляли определенные качества сервиса (задержки и ширина полосы пропускания). QoS профиль поддерживает управление следующими типами меток:
- Class of Service (CoS)
- Differentiated Services Code Point (DSCP)
Class of Service (CoS) – метка добавляется в L2 заголовок пакета и может содержать значение от 0 до 7. Это значение присваивается пакетам внутри гипервизора и может быть использовано для определения приоритетности пакетов как в буфере ESXi, то есть в пределах одного гипервизора, так и в физической сети.
Differentiated Services Code Point (DSCP) – это метка может разбивать трафик по приоритетам от 0 до 63. DSCP метка помещается в L3 заголовок пакета и учитывается роутерами при маршрутизации трафика в физической сети. Данная метка не учитывается при продвижении пакетов внутри буферов гипервизора и нужна сугубо для приоретезации пакетов в физической сети. И так как эта метка предназначена для физических устройств, она лепится на внешний L3 заголовок сформированного Geneve пакета.
Теперь о том, как NSX определяет какую метку какого типа лепить на какие пакеты.

По DSCP. У нас есть настройка Mode, которая определяет будет ли метка DSCP, назначенная гостевой системой учтена и дублирована во внешний Geneve заголовок, на основе которого пакет будет перемещаться по физической сети и соответственно получать определенный уровень сервиса (Trusted Mode). Или же на пакет будет прилеплена метка с приоритетом, определенным в профиле (Untrusted Mode) и не важно какое значение добавляет виртуалка. Настройка Priority как раз определяет это значение. Если используется Untrusted Mode, метки будут присваиваться так же и на пакеты в VLAN сегменте, в то время как Trusted Mode подразумевает трансляцию внутренней метки пакета во внешнюю, а Geneve заголовке и соответственно использование Overlay сегмента. Естественно в случае VLAN сегмента, метки будут помещаться в оригинальный IP заголовок и физическая сеть будет ориентироваться на него при пересылке пакета, так как Geneve заголовок отсутствует.
По CoS. Все просто, настройка Class of Service определяет значение метки в L2 заголовке.
Для того что бы предотвратить перегрузку физических линков наших гипервизоров мы можем воспользоваться до боли похожими на Traffic Shaping из vSphere настройками скорости, пиковой скорости и размером Burst входящего и исходящего трафика.
Segment Security Profile
Профиль безопасности. Он диктует какие механизмы будут задействованы на профиле для обеспечения базовой L2 и L3 защиты портов в сегменте от типовых атак. Эти механизмы проверяют входящий в сегмент трафик и блокируют тот который этим политикам не отвечают.

Пробежимся по этим механизмам.
BPDU Filter – как видно из названия блокирует весь BPDU трафик, который как то попал в сегмент. На самом деле это очень важная настройка, которая может предотвратить изоляцию хоста, в случае если, какая-либо виртуальная машина отошлет с сеть BPDU пакет, и он доберется до физического коммутатора, а там настроен BPDU Guard на принимающем порту. Но это другая тема для другого поста. Лучше его включать.
BPDU Filter Allow List – тут мы можем указать MAC адреса назначения, BPDU трафик до которых будет разрешен при включенном BPDU Filter. Имеются ввиду внешние физические маки.
Перейдем к разделу DHCP:
Server Block – при включении режет трафик, направленный от DHCP сервера клиенту.
Client Block – блокирует запросы от клиента к серверу.
Server Block/Client Block IPv6 – думаю объяснять не нужно что они делают.
Block Non-IP Traffic – при включении этого фильтра будет блокировать весь трафик кроме IPv4, IPv6, ARP, GARP и BPDU.
RA Guard – запретить IPv6 router advertisements.
Rate Limits – создаем лимит для broadcast и multicast трафика в сегменте. Задается указанием количества пакетов в секунду, а не скоростью. Может предотвратить широковещательный шторм в сегменте. Рекомендуется задавать значение около 10 пакетов в секунду на все четыре поля для того что б совсем не ликвидировать широковещательный трафик.
SpoofGuard Profile
Последний в списке, но не по значению SpoofGuard. Он имеет лишь одну настройку – вкл/выкл, которая регламентирует соответственно включен ли механизм SpoofGuard в сегментеb или на конкретном порту, к которому добавлен этот профиль. Теперь о том, что делает этот механизм будучи включенным. Главная суть этого механизма в том, чтобы предотвратить передачу трафика VM, если IP/MAC/VLAN (если сегмент в VLAN TZ) отправителя в пакете, отправленном этой VM отличается от того что в Realized Bindings List порта. То есть, когда пакет отправляется с порта в сегменте, его IP, MAC отправителя и VLAN (если в сегменте транком подаются VLAN к портам) сверяются с содержащимися в Realized Bindings List этого порта и, если они не совпадают, то пакет дропается. А если в тоже время с порта попытается уйти нормальный кадр, с IP/MAC/VLAN источника соответствующими Realized Bindings List, то его пропустят. Проверка происходит по всем трем пунктам IP/MAC/VLAN.
Как пакеты путешествуют по сегменту?
В этом разделе мы разберем что еще нужно помимо того, что мы рассмотрели выше для перемещения пакетов в сегменте NSX, проследим за путешествием маленького пакета в огромном сегменте, а также посмотрим, как распространяется BUM трафик и узнаем про ARP Suppression.
TEP/MAC/ARP таблицы
Итак, для того что бы пакеты виртуальных машин и прочих потребителей виртуально сети пересылались и могли путешествовать между хостами, им хостам нужно знать, через какой туннель и какому хосту нужно слать тот или иной фрейм. На помощь приходят таблицы сопоставления. Эти таблицы работают так же как MAC таблицы на физических коммутаторах. В физической сети свитч решает на основе MAC таблицы в какой порт отправлять пакет. На основе похожих таблиц в NSX и хост знает за каким TEP интерфейсом скрывается порт виртуальной машины, которому нужно доставить пакет. Но не все так просто, в NSX подобных таблиц несколько:
- TEP Table
- MAC Table
- ARP Table
Помимо заполнения этих таблиц присутствует задача в их заполнении и поддержки в актуальном состоянии, а это комплексная задача, учитывая, что хостов несколько и нужно как-то эти таблицы держать актуальном состоянии на всех хостах одновременно.
TEP Table
Содержит сопоставления VNI-ID сегмента к IP TEP интерфейса хоста. Выглядит это так:
| VNI сегмента | TEP IP хоста |
| 5700 | 192.168.30.2 |
| 5701 | 192.168.30.2 |
Запись VNI сегмента-TEP IP добавляется в таблицу при включении VM в этом сегменте. Итак, мы знаем за какими нашими локальными TEP-ами прячутся какие сегменты, супер. Но что дальше, нам то эта информация зачем? А затем что бы регулярно отправлять эту таблицу на Central Control Plane (CCP) по Management Network. А CCP в свою очередь получая со всех хостов такие таблицы, формирует из них одну и затем рассылает ее хостам. Таким образом все хосты получают информацию о том какие TEP-ы принимают участие в пересылке пакетов в определенном сегменте. Теперь на каждом хосте таблица стала такой.
| VNI сегмента | TEP IP хоста |
| 5700 | 192.168.30.2 192.168.30.3 |
| 5701 | 192.168.30.2 192.168.30.3 |
MAC Table
Когда виртуальная машина подключается к сегменту, ее MAC адрес сопоставляется с TEP IP, который обслуживает данный сегмент. Эта информация записывается в таблицу на хосте.
| VNI сегмента | VM MAC | TEP IP хоста |
| 5700 | AA:AA:AA:AA | 192.168.30.2 |
| 5701 | BB:BB:BB:BB | 192.168.30.2 |
Точно так же эта информация отправляется в CCP, с которого потом прилетает консолидированная таблица MAC-TEP по всем хостам.
| VNI сегмента | VM MAC | TEP IP хоста |
| 5700 | AA:AA:AA:AA CC:CC:CC:CC | 192.168.30.2 192.168.30.3 |
| 5701 | BB:BB:BB:BB DD:DD:DD:DD | 192.168.30.2 192.168.30.3 |
Теперь каждый хост в Транспортной Зоне знает за каким TEP расположен определенный MAC. Отлично, этого вполне достаточно для полноценной коммутации пакетов, почти как в физической сети.
ARP Table
Но виртуальная сеть на этом не останавливается. Для реализации ARP Suppression о которой мы говорили ранее NSX-у нужно знать сопоставление IP-MAC машин. Как мы помним из предыдущего раздела у нас есть Realized Bindings List, в котором и содержаться IP-MAC-VLAN маппинги. Этой информацией заполняется наша ARP таблица на хосте и отправляется на CCP, где прилетевшие таблицы со всех хостов складываются в одну, и она рассылается обратно хостам. И мы получаем:
| VNI сегмента | VM IP | VM MAC | TEP IP хоста |
| 5700 | 172.16.33.25 172.16.33.26 | AA:AA:AA:AA CC:CC:CC:CC | 192.168.30.2 192.168.30.3 |
| 5701 | 163.15.240.21 163.15.240.22 | BB:BB:BB:BB DD:DD:DD:DD | 192.168.30.2 192.168.30.3 |
Теперь Data Plane на Транспортных Нодах обладает всей необходимой информацией о том, кто и где, чтобы пересылать пакеты и уменьшать количество широковещательных запросов с помощью ARP Suppression. Эти таблицы рассылаются c CCP не только гипервизорам, но и «эджам». Потому как Edge Nodes так же учувствуют в пересылке трафика на L2 и на них так же есть TEP интерфейсы. Пакеты из физического мира попадают в матрицу виртуальную сеть только через Edge, соответственно ему нужно знать за каким TEP находится нужная VM.
Путешествие пакетов между хостами
Во время прочтения этой статьи мы знакомились с компонентами логического свитчинга в NSX-T, узнали, что для чего нужно и как это работает. Теперь настало время сложить все узнанное в единую картинку и посмотреть, как функционирует уровень L2 сетевой модели в виртуальной сети NSX. Рассмотрим, как фреймы путешествуют по виртуальной сети в случае Unicast и BUM трафика.
Путь пакета Unicast
В нашем примере VM-1 хочет отослать пакет VM-2.VM-1 отсылает пакет с адресом назначения IP 2 (1).

Гипервизор ESXi-A принимает пакет на Data Plane, смотрит его адрес назначения и понимает, что пакет предназначен VM, которая на нем не расположена. Он проверяет присланные с CCP таблицы и видит, что IP машины, которой предназначен пакет располагается за TEP с IP 10.20.10.12. ESXi-A инкапсулирует пакет VM-1 Geneve заголовком и указывает в адресе источника IP своего TEP интерфейса (10.20.10.11), а в адресе назначения IP TEP хоста ESXi-B (10.20.10.12), добавляет в заголовок VNI ID сегмента (5000). Инкапсулированный пакет отправляется в путешествие по физической сети до TEP ESXi-B (2).

Пакет доставляется физической сетью до ESXi-B. Гипервизор принимает пакет на своих аплинках и передает TEP интерфейсу (3).
ESXi-B производит декапсуляцию пакета Geneve. Смотрит адрес назначения оригинального пакета, определяет, что он предназначен для VM-2 и пропихивает фрейм в порт, на котором числиться в Realized Binding List IP адрес назначения (4).

Задача выполнена и пакет доставлен. VM-2 ответит VM-1 по такому же принципу и ее ответный пакет проделает аналогичный путь, только наоборот. Таким образом происходит пересылка Unicast пакетов внутри сегмента NSX.
Пересылка BUM трафика
Для начала вспомним, что такое BUM трафик. Это широковещательный трафик broadcast, unknown unicast и multicast, сокращенно BUM. Данный трафик адресован множественным получателям. Мы не будем вникать в его технические нюансы, подразумевая что читатель знаком с ними, а если нет, то бегом сюда.
Итак, перед NSX-T стоит задача пересылки такого трафика. Из предыдущего примера мы знаем, как пересылается обычный unicast пакет между хостами. Но как быть с пакетом, который должен попасть в несколько портов сегмента? Логично, его нужно транслировать до необходимых TEP интерфейсов в сегменте за которыми расположены порты назначения. В случае broadcast это все TEP в сегменте. А после доставки на гипервизор, данный пакет будет разослан всем портам, которым он предназначен. Остается уточнить как именно наш широковещательный пакет будет рассылаться по гипервизорам. Существует два режима рассылки BUM трафика в NSX-T:
- Head Replication
- Hierarchical two-tier replication
Head Replication – Транспортная Нода источник сама рассылает широковещательные пакеты до каждого TEP интерфейса в сегменте, неважно находиться ли IP TEP-ов назначения в одном L2 домене с IP TEP источником или нет. Каждому TEP-у по копии пакета. Далее получившие данный пакет хосты рассылают его копии всем портам назначения в сегменте.

Hierarchical Two-Tier Replication – в данном режиме Транспортная Нода источник BUM трафика берет на себя рассылку широковещательного пакета всем TEP-ам в одном с ней L2 домене. Если есть TEP-ы, которые так же должны получить этот широковещательный пакет, но их IP адреса находиться в другом L2 домене, то есть в другой подсети, то происходит следующее. ТН источник рандомно выбирает в каждой сети один TEP (Proxy TEP), на который отправляется копия широковещательного пакета. В заголовке Geneve данного пакета ставиться специальная метка. Хост назначения получает этот пакет на своем TEP интерфейсе, проверяет заголовок, видит метку и рассылает копии этого пакета всем остальным TEP-ам в его сети, но метку с них снимает. А также пропихивает полученный кадр своим локальным получателям. Остальные хосты получают наш пакет и рассылают свои получателям.

Данные режимы настраиваются на каждом сегменте.