На этой странице мы рассмотрим утилиту для мониторинга и траблшутинга ESXi хостов – ESXTOP. Это очень нужная виртуальному админу утилита, которая может отображать практически все метрики производительности гипервизора ESXi. Благодаря ей можно отследить и продиагностировать в следствии чего тормозит виртуальная машина, сеть на хосте и многое другое. ESXTOP представляет из себя консольную утилиту наподобие top, который присутствует во всех Linux системах, но более доработанный и заточенный под гипервизор. Использовать esxtop можно подключившись к интересующему нас хосту через SSH либо же через DCUI консоль. Как нетрудно догадаться нам нужна команда esxtop, запущенная в shell гипервизора.
У ESXTOP есть несколько режимов работы:
- Интерактивный – режим по умолчанию, в котором вы видите показатели производительности в реальном времени.
- Batch режим – с помощью него можно производить «запись» метрик esxtop за определенное время в файл, для дальнейшего воспроизведения в других утилитах.
- Replay режим – используется для воспроизведения снятых показателей из vm-support bundle.
В данной статье мы остановимся исключительно на первом режиме и сосредоточимся на показателях ESXTOP, исходя из чего они высчитываются и что обозначают. У утилиты есть несколько так называемых разделов производительности или по-другому – граф. В каждой из которых мы можем наблюдать данные производительности по какому-то определенному компоненту гипервизора. Например, метрики производительности процессора или дисковой активности. Каждая графа доступна нам из esxtop при нажатии определенного ключа (клавиши). Остановимся на каждой графе по отдельности.
Рower (ключ p)
Ключ p переводит esxtop в режим отображения о питании CPU и его рабочих параметрах, загрузке. В этой графе представлены метрики с точки зрения каждого физического или логического ядра на сервере, его питания и фактической нагрузке. Тут мы можем определить какое ядро находиться в каком состоянии, на какой частоте и насколько нагружено в настоящее время.
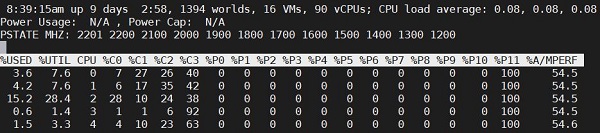
Мы видим вверху общие сведения и статистику о работающих VM, аптайме и Load Average, но это не самое интересное. Так же видим сколько процентов времени то или иное ядро находится в том или ином P state или С state.
Для того что бы хорошо ориентироваться в данной графе, нужно знать немного теории о том, как работают P/C состояния (по-другому P/C — states) и как они влияют на производительность и частоту ядра внутри процессора. А также немаловажно понимание технологий TurboBoost и Hyperthreating. Проясним основные моменты в этой теории.
P — состояния (P—state), регулируют и задают частоту работы ядра, когда ядро выполняет инструкции, то есть находиться в состоянии работы. В зависимости от модели и архитектуры CPU, а также настройках в UEFI, ядру может быть доступно разное количество P состояний. На скрине выше мы видим их 12 штук и каждому соответствует определенная частота работы. Частоты относительно P состояний перечислены в графе PSTATE MHZ на том же скрине для удобства. P0 является самым производительным состоянием и подразумевает работу ядра на самой высокой частоте, которая доступна ядру. А также P0 включает TurboBoost.
С – состояния (C—state), регулируют глубину «сна» ядра. Когда ядро не нагружено работой, не исполняет инструкции и соответственно находиться в бездействии, но тратит энергию, системой может быть принято решение частично или полностью на какое-то время вывести ядро из работы, выключив питание на каких-то определенных его компонентах или даже на всех (что зависит от глубины C состояния), тем самым экономя энергию и уменьшая тепловыделение. Каждое более глубокое состояние (от С0 до С8) обуславливается отключением (обесточиваем) какого-либо компонента ядра, будь то сброс кеша или отключения питания и частот вообще. Следует понимать, чем глубже ядро засыпает (чем выше C состояние), тем дольше оно будет «просыпаться» или другими словами переходить в режим исполнения инструкций. И это в свою очередь может сказаться на производительности VM. C0 соответствует активному состоянию, то есть ядро находиться в каком-либо P состоянии.
TurboBoost – это фишка процессоров Intel и ее прямое назначение – это увеличивать частоты на ядре выше базовой при необходимости на какое-то время. Например, возьмем процессор Xeon E5-2620 v3, он имеет базовую частоту 2,4 GHz, но TurboBoost может разогнать его до 3,2 GHz на определенное время. Вечно TurboBoost не будет держать максимальную частоту на ядре, даже если это нужно. Время, на которое TurboBoost может дать «ускорение» зависит от того, насколько нагрет процессор и сколько электричества мы сэкономили при нахождении ядер в низких P состояниях или C состояниях. И если в результате работы CPU не нагревается, и мы экономим электроэнергию успешно, то при появлении нагрузки на каком-либо ядре, TurboBoost может хорошенько накинуть частот на продолжительное время, что положительно скажется на работе приложения на этом ядре. То есть чем менее нагруженнее CPU, тем больше и чаще можно пользоваться ToorboBoost-ом. Без включенных в BIOS или UEFI P и C состояний, TurboBoost работать не будет.
Как упоминалось выше питание, и частота ядер CPU зависят от выставленного P или C состояния на ядре. То есть с помощью этих состояний можно управлять мощностью ядер. P и C состояния могут управляться как ОС, так и самим «железом», а могут быть и вовсе выключены и CPU будет всегда работать на базовой частоте. Как будет осуществляться это управление зависит от настроек в BIOS или UEFI, а также от выбранного режима в Power Policy на ESXi хосте. Например, если вы выбрали Power Policy – Max Performance, то P и C состояния не будут работать и ядра CPU будут по умолчанию всегда жить на самых высоких частотах. Но это отдельная тема, очень хорошо описанная в Host Resources Deep Dive.
Далее нам нужно знать еще кое-что. Существуют некоторые счетчики CPU, по которым «железо» может производить расчеты фактически выполненной работы:
- Time Stamp Counter (or TSC) – 64 битный регистр в процессоре, который считает отработанные такты в независимости от изменения частоты ядра. То есть не учитывает P или C состояния и ToorboBoost.
- Unhalted Cycles – другой счетчик, который считает так же все отработанные такты, но зависит от частоты работы ядра и соответственно его показатели могут меняться в зависимости от изменения частоты работы ядра если включен power-management или Hyperthreating.
- Wall Clock Time – счетчик реально прошедшего времени.
На их основе многие метрики esxtop выводят данные.
Hyperthreating – так же технология Intel, с помощью которой одно физическое ядро может производить вычисления сразу двумя потоками. Конечно эти два потока или логических ядра присутствуют в рамках одного физического, используют его кеш, его шину и так далее. По сути то работает одно физическое ядро, но благодаря параллельным конвейерам инструкций и данных, это одно физическое ядро не тратит время на простой и ожидание, а неимоверно быстро переключается между обработкой обоих потоков. Подробно эту технологию мы рассматривать не будем, не в контексте esxtop. Но нам нужно понимать, как происходит вычисление нагрузки и выполненной работы на каждом из логических ядер при включенном Hyperthreating.
Итак, перейдем к метрикам ESXTOP в контексте ключа p.
%USED — Показывает сколько времени ядро (или поток в случае включенного Hypertreating) выполняло «полезную работу». %USED (основан на Unhalted Cycles) = (unhalted cycles)/wall clock time. Если в системе не используется Power management, С/P — states и Hyperthreating то %UTIL=%USED.
%USED и Power Management.В случае использования Power Management, P/C — states, частота работы ядра будет нефиксированной, соответственно значение %USED, основанное на зависимом от частоты счетчике, не будет равно %UTIL. При низкой частоте работы ядра %UTIL будет выше чем %USED и наоборот, при включении TurboBoost, %USED будет выше чем %UTIL.
%USED и Hyperthreating. При включенном HT каждое физическое ядро имеет два логических и %USED потока считается по другому принципу. Если два потока на одном ядре работают параллельно 100% времени (%UTIL каждого=100%), то %USED каждого будет равен — (unhalted cycles)/wall clock time * 62.2%, что значит, что два потока на одном ядре могут достичь суммарно 125%. Почему 62,2% а не 50%, ведь это «половинка» ядра? Объяснение этому в том, что два потока используют параллельные конвейеры инструкций и данных, что значительно увеличивает, это хорошо расписано в Host Resources Deep Dive. Если же активен только один поток внутри одного ядра, то его %USED= (unhalted cycles)/wall clock time * 50%.
%UTIL — Показывает сырую утилизацию ядра или потока. В чем разница между %USEDи %UTIL? Очень частый вопрос. Напомню, что в зависимости от использования Hyperthreating каждый CPU будет отображать статистику потока или статистику ядра. %UTIL (основан на TSC) = (циклы, посчитанные TSC)/wall clock time. Он не учитывает изменяющуюся частоту при Power Management. Если включен Hyperthreating, и один из потоков загружен полностью, то его %UTIL будет 100%, если на ядре загружены одновременно оба потока, для каждого из них %USED будет равен 100%.
'+' means busy, '-' means idle.
(1) PCPU 0: +++++----- (UTIL: %50 / USED: %50)
PCPU 1: -----+++++ (UTIL: %50 / USED: %50)
(2) PCPU 0: +++++----- (UTIL: %50 / USED: %25)
PCPU 1: +++++----- (UTIL: %50 / USED: %25)
(3) PCPU 0: +++++----- (UTIL: %50 / USED: %40, i.e. %30 + 20%/2)
PCPU 1: ---+++++-- (UTIL: %50 / USED: %40, i.e. %20/2 + %30)
%A/MPERF – Данный счетчик появился в версии 6.5, показывает фактическую производительность ядра или потока относительно частотам. По этому значению можно определить фактическую частоту работы ядра или потока. На скрине сверху мы видим значение 54.5, что говорит нам о использовании ядром половины своей частоты, это можно так же подкрепить тем что ядро 100% времени проводит в P11 состоянии, что равняется 1200MHZ. А если мы взглянем на пару %USED=3.6 и %UTIL=7.6, мы определим разницу почти в половину между этими значениями, что так же говорит о задействовании около половины от максимальной частоты в 2201MHZ (Xeon E5-2699 v4).
Использование CPU (ключ c)
Отображение использования виртуальными машинами и процессами ESXi ресурсов CPU.
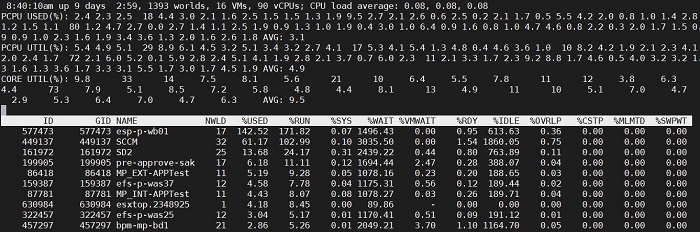
Тут мы наблюдаем различную статистику. Сосредоточимся вверху и выделим три параметра.
PCPU USED% — Знакомая метрика, не так ли? Да именно. Тут она отображает ровно тоже самое что и в показателе при использовании ключа «p» – количество «полезной» работы ядра или при включенном Hyperthreating — потока.
PCPU UTIL% — Так же, как и в случае ключа «p», отображает «сырую» утилизацию ядра или потока.
CORE UTIL% — это поле появляется только при включенном Hyperthreating, при выключенном его нет. Поле отображает утилизацию ядра целиков, но не всегда является суммой PCPU UTIL% потоков. Эта метрика отображает произведенные такты ядра в независимости от того активны ли оба потока или же активен один или же активны оба, но в разное время.
Ниже посмотрите, как меняется CORE UTIL% ядра в зависимости от PCPU UTIL% каждого логических ядра.
'+' means busy, '-' means idle.
(1) PCPU 0: +++++----- (%50)
PCPU 1: -----+++++ (%50)
Core 0: ++++++++++ (%100)
(2) PCPU 0: +++++----- (%50)
PCPU 1: +++++----- (%50)
Core 0: +++++----- (%50)
(3) PCPU 0: +++++----- (%50)
PCPU 1: ---+++++-- (%50)
Core 0: ++++++++-- (%80)

Едем дальше, теперь рассмотрим виртуальные машины. VM представляются так называемыми world-ами, или процессами, которые шедулером назначаются для исполнения на потоки или ядра. Эти worlds или «миры» имеют свои ID и группируются в группы с GID виртуальной машины. Так же у ESXi есть свои служебные миры.
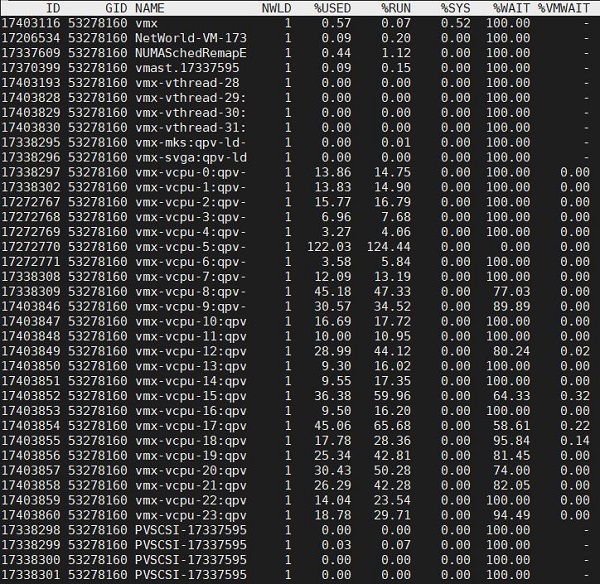
Есть возможность оставить в выводе только VM, для этого следует приметить ключ «V». Можно при просмотре нажать «e», ввести GID интересующей нас машины и посмотреть все ее миры, отсортированные по GID. Тут мы увидим различные типы миров, каждый из который исполняет свою функцию. Это важная информация, которая поможет лучше разобраться с устройством VM изнутри. Итак, погнали:
- vmx – административный процесс нашей виртуальной машины
- vmx-vcpu-XXX – процесс виртуального процессора нашей VM.
- vmx-mks – процесс, обрабатывающий ввод вывод с клавиатуры, мыши и монитора
- Net-World-VM-XX – процесс обрабатывающий исходящий траффик с VM (по умолчанию один на всю VM в независимости от количества vNIC у нее)
- PVSCSI-XXXX – процесс виртуального адаптера SCSI, на каждый адаптер свой процесс (зависит от типа адаптера у машины, в нашем случае это ParavirtualSCSI)
- vmx-svga – процесс графического адаптера нашей VM.
Каждый из этих миров может одновременно занять только один поток или ядро. Разберемся с метриками:
%USED – знакомая нам метрика. Отображает сколько времени виртуальная машина использует CPU. У машины целиком может быть использование больше 100%, так суммарно ее миры используют несколько ядер. Один же мир в составе машины не может использовать более 100%.
%RUN – отображает время полезной работы VM. Когда фактически исполняется ее код.
%SYS – время, потраченное на обработку CPU ввода-вывода. Например, обработка сетевой активности, активность процесса Net-World-VM-XX будет почти вся учтена как %SYS.
%WAIT – время, которое машина не активна, учитывая ожидание ввода-вывода или машина может быть просто неактивна (IDLE). %WAIT = %VMWAIT + %IDLE + %SWPWT. Не совсем конкретная метрика, глядя на нее трудно понять, что служит причиной ожидания.
%VMWAIT – время, которое VM ждет событий с VMKERNEL (может быть ввод-вывод).
%RDY – время которое VM готова исполнять инструкции, но вынуждена ждать пока шедулер назначит ее на исполнение. %RDY включает в себя %MLMTD и говорит о том, что машина испытывает недостаток процессорного времени.
%IDLE – процент времени, который VM проводит в бездействии, в %IDLE может находиться только «миры» vCPU машины. Эта метрика учитывается в %WAIT.
%OVRLP – отображает процент времени, которое было потрачено VM на «перекрытие». Это время, в которое исполнение кода текущей VM было прервано на ядре и был исполнен код обработки ввода-вывода другой VM. У текущей машины — это время засчитается как %OVRLP, а у другой как %SYS.
%CSTP – процент времени, который VM готова исполняться, но вынуждена ожидать пока все необходимые pCPU будут для этого доступны. К примеру эта метрика характерна для машин с большим количеством vCPU, когда машина не может получить для исполнения своих vCPU миров сразу все необходимые pCPU.
%MLMTD – указывает на время, в течении которого VM готово исполнять код, но упирается в Limit.
%SWPWT – количество времени, которое «мир» ждет пока страница памяти будет прочитана из свопа VM.
SWTCH/s – указывает сколько раз было переключение контекста при исполнении текущего «мира».
MIG/s – указывает количество раз, которое «мир» мигрировал с одного pCPU на другой, к примеру, ввиду большой загрузки этого pCPU
QEXP/s – отображает сколько раз в секунду у «мира» заканчивается промежуток времени, данный на исполнение, так же учитывает, количество раз, когда «мир» переходит в WAIT, до того, как отведенное на исполнение время закончится.
WAKE/s – сколько раз в секунду «мир» переходит из WAIT в READY.
%LAT_C – отображает процент так называемого STOLEN TIME. STOLEN TIME – украденное у VM время или циклы в процессе работы из-за %OVRLP, %RDY, %CSTP, работе ядра на низкой частоте, издержек из-за HT.
%DMD – Отображает сколько ресурсов процесс запрашивает, сколько бы он взял в идеале.
AUNITS — Единицы выделения ресурсов. Для VM — mhz. Для процессов ESXi — pct.
Memory (ключ m)
Отображает статистику оперативной памяти ESXi процессов и виртуальных машин.
Перед тем как мы погрузимся в сухое описание метрик, следует упомянуть теоретическую часть. Итак, что следует знать?
MEM OVERHEAD – Дополнительный объем оперативной памяти виртуальной машины, используемый для хранения различных структур данных, необходимых для накладных расходом при функционале VM. Размер этого пространства зависит от конфигурации VM
MINFREE — объем памяти необходимый гипервизору для работы. Высчитывается довольно интересным образом. Можно привести таблицу ниже, опять же из всеми любимой книги. Это значит, что с первых 4-х гигабайт доступной памяти резервируется 6% от этого объема, то есть 245MB, затем из последующих с 4-х по 12 гигов резервируется 4% и так далее согласно таблице, в итоге вся эта память суммируется и мы получаем значение minfree. Подобный алгоритм применим к версиям ESXi после 5.0.
| резервируемый процент от > | Объема памяти |
| 6% | 0-4GB |
| 4% | 4-12GB |
| 2% | 12-28GB |
| 1% | Remaining memory |
MEMORY STATES – состояния памяти, это относится к тому, сколько свободной памяти осталось на хосте. Этот показатель напрямую зависит от значения MINFREE. И снова таблица.
| memory state | Threshold in Percentage |
| High | Higher than or equal to Mem.MinFree |
| Clear | <100% of minFree |
| Soft | <64% of minFree |
| Hard | <32% of minFree |
| Low | <16% of minFree |
От состояния памяти зависит какие рекламационные техники будут применяться для ее освобождения. А это:
TPS — Transparent Page Sharing. Вкратце занимается дедуплицированием одинаковых страниц памяти. Работает только со страницами 4КБ, со страницами по 2МБ не работает и при достижении состояния Clear принудительно «разламывает» большие страница на маленькие по 2КБ и их потом обрабатывает.
BALLOONING – Вкратце отжимает память у виртуальных машин через драйвер Balloning внутри гостевой ОС.
COMPRESSION – Сжатие страниц памяти, происходит после того как отработала дедупликация (TPS).
SWAPPING – свопирование страниц памяти.
BLOCKING – гипервизор перестает выделять страницы памяти для VM, при этом гостевая система может прекратить работу или выдать BSOD.
Ниже таблица, при каком состоянии какая техника начинает работать.
| Mem state | TPS | BALOONING | COMPRESSION | SWAPPING | BLOCKING |
| HIGH | Нормальная активность | ||||
| CLEAR | TPS разламывает страницы | ||||
| SOFT | + | + | |||
| HARD | + | + | + | ||
| LOW | + | + | + | + |
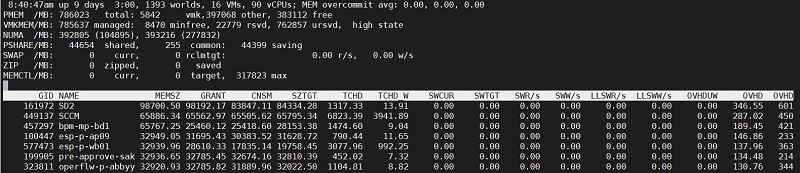
Теперь перейдем к ESXTOP. Вверху мы видим отображение общей статистики по памяти. Тут расположились следующие показатели:
PMEM – общее количество оперативной памяти хоста в мегабайтах. Далее vmk – память, используемая гипервизором, other – память VM, free – свободная.
VMKMEM –память доступная гипервизору. С подробностями и текущем состоянии
NUMA – сколько у нас NUMA нод и сколько на каждой доступно памяти
PSHARE – статистика по TPS. Как говорилось ранее TPS работает всегда по умолчанию и тут мы видим его показатели в мегабайтах.
SWAP – сколько в данный момент памяти ушло в своп.
ZIP – сколько в данный момент сжато.
MEMCTL — статистика использования Balloon Driver
Переходим к показателям VM или «миров»:
MEMSZ – объем памяти, сконфигурированный на VM. MEMSZ = GRANT + MCTLSZ + SWCUR + нетронутый объем.
GRANT — Granted память.
CNSM – Consumed память.
SZTGT – Целевой объем памяти, который будет выделен VM, включает в себя Overhead.
TCHD – Объем памяти, который активно используется машиной, регулярно считывается и записывается.
TCHD_W — Объем памяти, который активен на запись.
SWCUR – сколько сейчас использовано МБ свопа виртуальной машиной
SWTGT – сколько VM собирается достичь МБ использования свопа.
SWR/s – Скорость чтения данных из свопа виртуальной машиной.
SWW/s – Скорость записи данных в своп виртуальной машины.
LLSWR/s
LLSWW/s
OVHDUW – Объём памяти, зарезервированный VMX процессом.
OVHD – Объем памяти, потребленный overhead.
OVHDMAX – Максимальный объем памяти, который может использовать overhead
ZIP/s – компрессия памяти в секунду.
UNZIP/s – декомпрессия памяти в секунду.
VM Disks (ключ v)
Отображает статистику, сгруппированную по VMDK дискам виртуальных машин. Также, как и в случае с метриками по CPU, можно при использовании ключа «е», задать GID интересующей нас VM и получить развернутый вид по ее VMDK дискам.
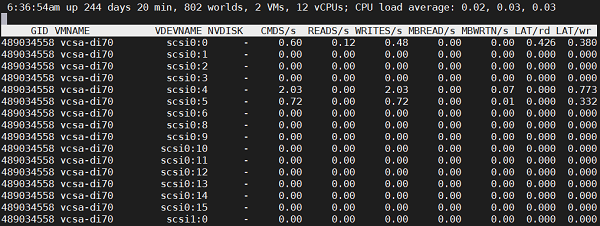
VDEVNAME – обозначение VMDK, отображает фактически к какому контроллеру и каким портом подключен.
NVDISK – при свернутом виде отображает количество VMDK.
CMDS/s – количество команд в секунду.
READS/s – команд на чтение с диска в секунду.
WRITES/s – команд записи на диск в секунду.
MBREAD/s – МБ прочитано в секунду.
MBWRTN/s – МБ записано в секунду.
LAT/rd – Задержка на чтение в ms.
LAT/wr – Задержка на запись в ms.
Disk Device (ключ u)
Емкая панель. Тут отображена статистика по физическим устройствам, подключенным к ESXi. Тут достаточно много метрик.

Тут мы сталкиваемся с понятием очередей (Queues). Нужно понимать, что очереди, в которых у нас прибывают команды, до того, как отправляются исполняться блочным устройством представляют собой многоступенчатую конструкцию на всем пути следования команды от ядра гостевой ОС до физического носителя на СХД и в ESXTOP мы отслеживаем только очереди со стороны хоста. Рассмотри очереди на ESXi хосте:
Очередь на виртуальном SCSI адаптере – это самая первая техническая очередь, куда гостевая система скидывает через драйвер команды ввода-вывода. Следует заметить, что внутри самой гостевой операционной системы так же имеются очереди, но это за пределами данной темы. Глубина очереди виртуальный SCSI адаптеров по умолчанию 32, только у PVSCSI может быть от 64 и выше, максимум 256. Так же присутствует очередь самого виртуального жесткого диска, глубина которой не может составлять больше чем глубина виртуального адаптера.
Очередь в VMKERNEL. Далее наш IOPS попадает на обработку в гипервизор, затем в Storage Stack и там может провести какое-то время. Если время внушительное, то имеются проблемы с очередями ниже, в HBA или может быть нехватка процессорного времени на своевременную обработку.
HBA очередь. Тут есть одна общая очередь, которая в панели устройств (при использовании ключа «u») не отображается, о ней мы поговорим позже. И есть очереди для каждого устройства|LUN|хранилища, которые намного меньше размером.
Далее команда отправляется в путешествие по SAN сети, коммутаторам и СХД. Но это уже другая история. Перейдем к метрикам на панели. Метрики объема чтения-записи мы рассматривали ранее и перечислять их не будем.
PATH/WORLD/PARTITION – значение в этой коленке отображаются только тогда, когда мы с помощью ключей p/t/e раскрываем устройство с точки зрения путей/разделов/процессов.
DQLEN – это глубина очереди устройства|LUN|хранилища. Имеет статическое значение, зависящее от производителя HBA, но может быть изменено.
WQLEN – глубина очереди команд для «мира».
ACTIV – Кол-во занятых слотов в очереди уст-ва.
QUED – Если очередь устройства забита, то есть ACTIV=DQLEN, этот показатель будет увеличиваться, отображая IO/ps-ы, которые были удержаны до освобождения очереди устройства. Это говорит о наличии проблем, и вы заметите задержки на уровне гостевой системы. То есть все команды к хранилищу не умещаются в его очереди и вынуждены простаивать.
%USD – процент загрузки очереди LUN.
LOAD – отношение исходящих (ACTIV+QUED) команд к глубине очереди.
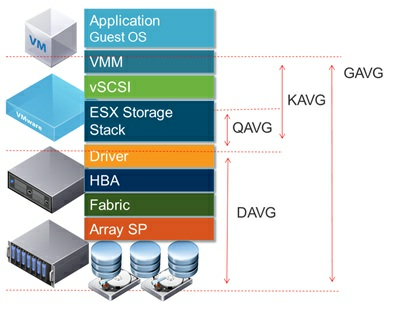
Далее идет ряд показателей, отражающих задержку команд с момента поступления последних на определенные уровни:
GAVG/cmd — Средняя задержка в ms на команду, которую ощущает гостевая система. Является суммой KAVG и DAVG.
KAVG/cmd — Средняя задержка в ms на команду, измеренная с момента попадания в kernel ESXi.
QAVG/cmd — Средняя задержка в ms на команду, вычитывающаяся с момента попадания команды в Storage Stack гипервизора. Является частью KAVG.
DAVG/cmd – Средняя задержка в ms на команду, измеренная с момента передачи в драйвер устройства.
Вышеперечисленные метрики могут встречаться в ESXTOP измеряя не только время задержки на команду и в других вариациях, но их смысл останется неизменен. Наглядно изображено на картинке.
Метрики отражающие ошибки, возвращенные устройством:
FCMDS/s – кол-во неудачных (failed) операций в секунду.
FREAD/s –кол-во неудачных (failed) операций чтения в секунду.
FWRITE/s — кол-во неудачных (failed) операций записи в секунду.
FRESV/s – кол-во неудачных (failed) операций резервации.
ABRTS/s – Количество прерванных (aborted) команд в секунду.
RESETS/s — Количество сброшенных (reset) команд в секунду.
Метрики, отражающие работу VAAI:
CLONE_RD – операции Block clone чтения.
CLONE_WR — операции Block clone записи.
CLONE_F – неудачные операции Block clone.
MBC_RD/s – МБ прочитанные операцией Block clone.
MBC_WR/s — МБ записанные операцией Block clone.
ATS – кол-во операций ATS.
ATSF — кол-во неудачных операций ATS.
ZERO – операции обнуления.
ZERO_F – неудачные операции обнуления.
MBZERO/s – МБ/сек обнулено.
DELETE – операции unmap.
DELETE_F – неудачные операции unmap
MBDEL/s – МБ/сек «unmap-лено».
HBA адаптер (ключ d)
Отображает информацию, похожую на статистику устройств, как в предыдущей секции, но ориентированную на HBA адаптеры.

Из важного стоит отметить AQLEN – показатель глубины общей очереди HBA адаптера из которой выделяется объем для очередей каждого устройства.
PATH – отображается при выборе через ключ «е» определенного адаптера.
NPTH – отображает количество путей на данном адаптере.
AQLEN – глубина очереди адаптера, зависит от производителя.
Далее следуют метрики аналогичные дисковому устройству, мы не будем их перечислять. Их интерпретация точно такая же, только относящаяся к статистике адаптера.
Network (ключ n)
В данной секции расположено все касающееся сетевой подсистемы гипервизора и виртуальных машин.

PORT-ID – идентификатор порта на виртуальном коммутаторе. Каждый порт, будь то vNIC, pNIC или VMKERNEL имеет идентификатор на виртуальном свиче.
UPLINK – Является ли порт аплинком.
UP – Если аплинк, то подключен ли он?
SPEED – скорость физического интерфейса.
FDUPLX – если физический адаптер, включен ли Full Duplex.
USED-BY – Обозначает что подключено в порт виртуального свича. Это может быть VM NIC, VMKERNEL порт (vmk#), физический адаптер (vmnic#) либо порт, использующийся для health check (Shadow of vmnic#).
TEAM-PNIC – vmnic, используемый для сетевой активности.
DNAME – Имя виртуального коммутатора.
PKTTX/s – Отправленных пакетов в секунду. Можно сортировать с помощью «t».
MbTX/s – МБ Tx в секунду. Можно сортировать с помощью «T».
PSZTX – средний размер отправленных пакетов в байтах.
PKTRX/s — Принятых пакетов в секунду.
MbRX/s – приянто МБ в секунду.
PSZRX – средний размер принятых пакетов.
%DRPTX – процент дропнутых исходящих пакетов.
%DRPRX – процент дропнутых входящих пакетов.
PKTTXMUL/s – количество исходящих мультикастовых пакетов в секунду.
PKTRXMUL/s — количество входящих мультикастовых пакетов в секунду.
PKTTXBRD/s — количество исходящих широковещательных пакетов в секунду.
PKTRXBRD/s — количество входящих широковещательных пакетов в секунду.